
Privacy Guides

Google Gemini Privacy Issue 2026: How AI Is Doxxing Real People
Google’s Gemini AI is leaking a Reddit user’s real phone number to strangers, and Google has ignored his privacy request for over a month. It’s not a glitch. It’s a new privacy threat we call AI doxxing, and your data is the fuel.
See where your personal data appears online
884,912 have already made this search
Privacy Writer
A. J. MercerAva J. Mercer
Updated
Read
5 min
See where your personal data appears online
884,912 have already made this search
What Happened: Google Gemini Started Handing Out a Real Phone Number
In late April 2026, a Google Gemini privacy issue went viral on Reddit. A user discovered the AI was inserting his real, private phone number as a “placeholder” in AI-generated content. Strangers had been calling him daily for weeks. The post got 1,435 upvotes and 143 comments. Another user replied that the same thing happened to him, with calls recorded as proof.
The user submitted a formal privacy request to Google. More than a month passed. No response.
This is the clearest documented case so far of what we call AI doxxing, when generative AI exposes a real person’s personal data to strangers. And it’s not isolated.
If your phone number is on a data broker site, the same thing could happen to you. Check what’s exposed for free with ClearNym.
Find out if your private details were exposed
884,912 have already used our search
This Has Already Happened to a Norwegian Father, a US Law Professor, and a Stalking Victim
Reddit users on the thread thought this was a quirky one-off. We’ve been tracking similar incidents for two years, and the picture is much darker than one phone number.
| Date | Victim | AI System | What Happened |
| 2023 | Jonathan Turley, US law professor | ChatGPT | Falsely accused of sexual harassment that never happened |
| 2024 | Arve Hjalmar Holmen, Norway | ChatGPT | Labeled as a child murderer who killed two of his sons, with the real number and gender of his children and his hometown woven in |
| 2025 | 143,000 users | ChatGPT, Claude, Copilot | AI conversations indexed on Archive.org with full names, phone numbers, and addresses |
| April 2026 | Jane Doe (lawsuit filed) | ChatGPT | Ex-partner used GPT-4o to generate fake “clinical-looking psychological reports” he distributed to her family, friends, and employer |
| April 2026 | Reddit user | Google Gemini | Real phone number handed out as a placeholder, daily harassment from strangers |
How Your Old Data Broker Profile Became AI Training Fuel
For over a decade, hundreds of data broker companies have aggregated phone numbers, home addresses, family connections, and employment history. They scraped public records, bought leaked databases, and harvested forgotten opt-out forms. Then AI labs scraped the open web to train their models, and the broker data was sitting right there.
Now large language models have memorized chunks of it. Researchers Carlini et al. proved in 2021 that even GPT-2 was already spitting out real phone numbers and email addresses verbatim. Newer research shows memorization scales log-linearly with model size: the bigger the AI, the more personal data it remembers.
This isn’t a problem AI labs can fix with a patch. The data is already inside the model, and retraining costs hundreds of millions per run.
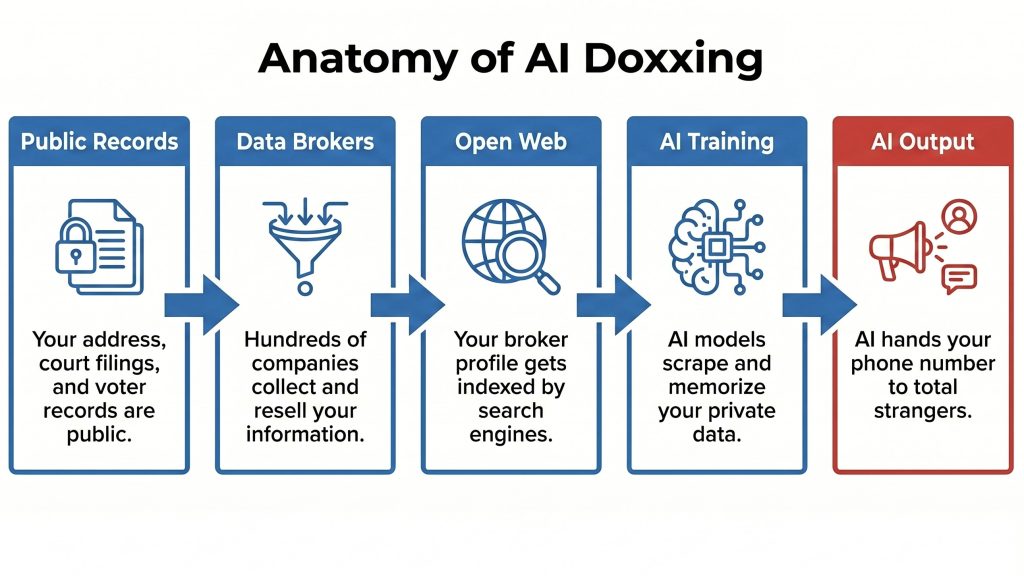
The Six Faces of AI Doxxing You Need to Know
We call this new threat class AI doxxing. It comes in at least six forms:
1. Memorization doxxing. The AI repeats real personal data verbatim because it was in the training set. The Gemini phone number case.
2. Hallucination doxxing. The AI invents accusations or false biographical details about a real person. The Holmen and Turley cases.
3. Sycophancy doxxing. The AI helps a stalker by validating their distorted view of a victim. The Jane Doe vs OpenAI lawsuit.
4. Public-share doxxing. Users accidentally publish AI conversations through share-links, exposing personal information indexed by search engines.
5. Cross-reference doxxing. The AI aggregates scattered public data points into a complete profile no single source contained on its own.
6. AI-psychosis doxxing. AI reinforces a stalker’s delusions, escalating real-world harassment. Documented by Futurism in at least 10 cases.
If your data is publicly accessible through people-search sites, you are exposed to every single one of these.
Which Data Categories Are Next at Risk
After tracking AI doxxing for some time, ClearNym’s team predicts five data categories most likely to surface in AI outputs over the next 12-18 months:
- Genealogy and family connections from Ancestry, MyHeritage, and FamilySearch
- Employment history and salary ranges from LinkedIn and Glassdoor
- Medical and wellness data from health forums and patient communities
- Home addresses and property records, similar to the Sam Altman home attack case.
- Political donation history from public FEC data
Any data category that lives on the open web is fuel for the next AI training run.
You Can’t Make AI Forget. But You Can Cut the Supply
You can’t make AI labs forget the data they already trained on. You can’t sue every broker that fed your information into the pipeline. Regulators are years behind.
But you can cut the supply.
- Google your own phone number, full name, and email. Most people are shocked by what’s public.
- Remove your data from people-search sites and data brokers. Less broker data means less ends up in the next AI training run.
- Never paste personal information into AI chats. Share-links can be indexed.
- Set up ongoing monitoring. Brokers re-list your information constantly.
- In the EU or California, file GDPR or CCPA requests with broker sites.
The most important step is the second one. Removing your data from broker sites breaks the chain that feeds AI training datasets. That’s exactly what ClearNym does, across 350+ broker sites, continuously.
Start your free scan at ClearNym and see how much of your personal information is already out there.
We remove your data for you - faster, verified, trackable.
Discover Which Sites Share Your Private Details—Instantly and Free.
884,912 have already used our search
References
- Reddit r/google, “Google’s AI is doxxing my real phone number.”
- The Washington Post, “ChatGPT invented a sexual harassment scandal and named a real law prof as the accused.”
- Noyb, “AI hallucinations: ChatGPT created a fake child murderer.”
- TechCrunch, “Stalking victim sues OpenAI, claims ChatGPT fueled her abuser’s delusions and ignored her warnings.”
- Obsidian Security, “143,000 Claude, Copilot, ChatGPT chats publicly accessible.”
- Carlini et al. (2021), “Extracting Training Data from Large Language Models.”
- Futurism, “AI Delusions Are Leading to Domestic Abuse, Harassment, and Stalking.”
- SafetyDetectives, “ChatGPT Leaks: We Analyzed 1,000 Public AI Conversations.”
- ClearNym, clearnym.com

Posted by Ava J. Mercer

